By ATS Staff - December 21st, 2025
Database MySQL Software Development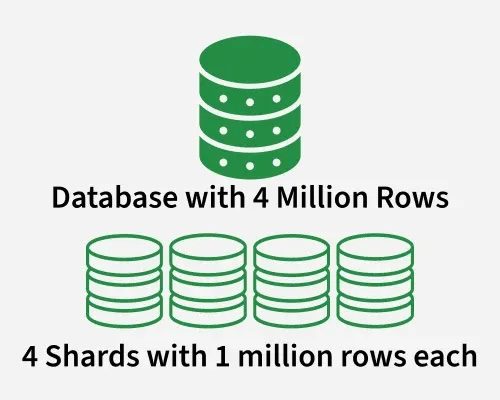
Introduction
In today's data-driven world, applications frequently encounter performance bottlenecks as their databases grow beyond the capacity of a single server. When your MySQL database starts struggling with billions of records, millions of queries per second, or terabytes of data, database sharding emerges as a critical solution for horizontal scaling. This architectural approach allows organizations to distribute data across multiple servers while maintaining application performance and availability.
What is Database Sharding?
Database sharding is a horizontal partitioning strategy that splits a large database into smaller, more manageable pieces called "shards." Each shard operates as an independent database, holding a subset of the total data. Unlike vertical scaling (adding more power to a single server), sharding enables horizontal scaling by distributing the load across multiple machines.
Key Benefits:
- Improved Performance: Parallel processing across shards reduces query latency
- Increased Storage Capacity: Overcome single-server storage limitations
- Enhanced Availability: Isolated failures affect only specific shards
- Geographic Distribution: Place data closer to users for reduced latency
When to Consider Sharding
Indicators You Need Sharding:
- Single database approaching storage limits (500GB+)
- Write/read throughput exceeding server capacity
- Slowing query performance despite optimization
- High-cost vertical scaling with diminishing returns
- Need for geographic data distribution
Alternatives to Consider First:
- Query optimization and indexing
- Database replication (master-slave)
- Caching strategies (Redis, Memcached)
- Database partitioning (within a single instance)
- Upgrading server hardware
Sharding Strategies
1. Key-Based (Hash) Sharding
Distributes data using a hash function on a shard key (e.g., user_id).
sql
-- Example: Sharding by user_id hash shard_number = hash(user_id) % total_shards
Pros: Even data distribution, predictable shard location
Cons: Difficult to reshard, cross-shard queries challenging
2. Range-Based Sharding
Distributes data based on value ranges (e.g., customer IDs 1-1000000 on shard1).
Pros: Easy to implement, efficient range queries within shards
Cons: Potential hotspot creation, uneven distribution
3. Directory-Based Sharding
Uses a lookup service to map data to shards.
Pros: Flexible shard management, easy resharding
Cons: Single point of failure in lookup service, added latency
4. Geo-Based Sharding
Distributes data based on geographic location.
Pros: Reduced latency for regional users, compliance with data sovereignty
Cons: Potential imbalance if user distribution changes
5. Composite Sharding
Combines multiple strategies for optimal distribution.
Implementation Approaches
Application-Level Sharding
The application contains logic to route queries to appropriate shards.
python
# Example Python implementation
def get_shard_connection(user_id):
shard_id = hash(user_id) % SHARD_COUNT
return shard_connections[shard_id]
Proxy-Based Sharding
Middleware (like ProxySQL, MaxScale) handles shard routing transparently.
Framework-Based Sharding
Using specialized frameworks like Vitess, Spider, or dbShards.
Step-by-Step Sharding Implementation
Phase 1: Preparation
- Analyze Data Access Patterns
- Identify frequently joined tables
- Document query patterns and transaction requirements
- Determine optimal shard key
- Design Shard Architecture
- Choose sharding strategy
- Determine number of initial shards
- Plan for future expansion
- Prepare Database Schema
- Ensure all tables include shard key
- Modify auto-increment keys
- Update foreign key relationships
Phase 2: Implementation
- Create Shard Infrastructuresql-- Create identical schema on each shard CREATE DATABASE shard_1; CREATE DATABASE shard_2; -- Repeat for all shards
- Implement Data Migration
- Use dual-write during transition
- Migrate historical data gradually
- Validate data consistency
- Update Application Code
- Implement shard routing logic
- Handle cross-shard queries
- Update connection management
Phase 3: Testing & Go-Live
- Performance Testing
- Load testing with production-like data
- Failover and recovery testing
- Cross-shard query optimization
- Monitoring Setup
- Implement shard-level monitoring
- Set up alerts for imbalances
- Track query performance per shard
Challenges and Solutions
1. Cross-Shard Joins
Problem: Joining data across shards is inefficient.
Solutions:
- Denormalize data where possible
- Maintain reference tables on all shards
- Perform application-side joins for small datasets
- Use specialized distributed query engines
2. Distributed Transactions
Problem: Maintaining ACID properties across shards.
Solutions:
- Design transactions to operate within single shards
- Implement eventual consistency patterns
- Use two-phase commit for critical operations
- Consider Saga pattern for complex transactions
3. Shard Rebalancing
Problem: Data distribution becomes uneven over time.
Solutions:
- Implement virtual sharding for easier migration
- Use consistent hashing to minimize data movement
- Schedule rebalancing during low-traffic periods
- Automate shard splitting procedures
4. Global Data Consistency
Problem: Maintaining referential integrity across shards.
Solutions:
- Use UUIDs instead of auto-increment keys
- Implement centralized ID generation
- Create global reference tables
- Employ distributed locking mechanisms
Tools and Technologies
MySQL Sharding Solutions:
- Vitess: Cloud-native scaling for MySQL (used by YouTube)
- ProxySQL: Advanced proxy with sharding support
- MySQL Fabric: Oracle's sharding framework
- Spider Storage Engine: Built-in partitioning engine
- dbShards: Commercial sharding solution
Complementary Technologies:
- Orchestrator: MySQL replication topology management
- Percona Monitoring and Management: Performance monitoring
- pt-online-schema-change: Safe schema modifications
- gh-ost: GitHub's online schema migration tool
Best Practices
1. Start Simple
- Begin with fewer shards than you think you need
- Use application-level sharding for initial implementation
- Avoid premature optimization
2. Monitor Religiously
- Track shard size and growth rates
- Monitor query performance per shard
- Set up alerts for shard imbalances
- Regularly analyze access patterns
3. Plan for Growth
- Design for at least 3x current capacity
- Implement automated shard splitting
- Document sharding procedures thoroughly
- Regular capacity planning reviews
4. Maintain Flexibility
- Abstract sharding logic from business logic
- Use configuration-driven shard mapping
- Implement feature flags for sharding changes
- Maintain rollback capabilities
Case Study: E-Commerce Platform Sharding
Challenge: A growing e-commerce platform with 50M users experiencing 10-second query delays during peak sales.
Solution Implemented:
- Chose customer_id as shard key using hash-based sharding
- Created 8 initial shards on geographically distributed servers
- Implemented Vitess for query routing and management
- Migrated user data over 72-hour period using dual-write strategy
Results:
- Query latency reduced from 10s to 200ms
- 99.9% uptime during Black Friday sales
- Linear scalability for future growth
- 40% reduction in database infrastructure costs
Future Trends
1. Cloud-Native Sharding
Managed services like Amazon Aurora, Google Cloud Spanner, and Azure Cosmos DB are simplifying sharding implementation.
2. Automated Shard Management
AI-driven shard rebalancing and predictive scaling are becoming more prevalent.
3. Polyglot Persistence
Combining MySQL sharding with specialized databases (graph, document, time-series) for different data types.
4. Serverless Database Sharding
Pay-per-use models with automatic scaling eliminate manual shard management.
Conclusion
MySQL database sharding represents a significant architectural investment that pays substantial dividends for growing applications. While introducing complexity in development and operations, it provides the scalability needed for modern, data-intensive applications.
The key to successful sharding lies in careful planning, thorough testing, and ongoing monitoring. Start with the simplest approach that meets your needs, document everything, and build incrementally. Remember that sharding is one tool in your scaling toolkit—often used in combination with caching, replication, and optimization techniques.
As database technologies continue to evolve, sharding implementations are becoming more automated and manageable. Whether you choose application-level sharding, a proxy-based solution, or a comprehensive framework like Vitess, the principles of careful design and gradual implementation remain constant.
For organizations facing genuine scaling challenges, MySQL sharding transforms database limitations from a growth barrier into a manageable engineering concern, enabling applications to scale to meet global demand while maintaining performance and reliability.
Popular Categories
Agile 2 Android 2 Artificial Intelligence 51 Blockchain 2 Cloud Storage 3 Code Editors 2 Computer Languages 12 Cybersecurity 8 Data Science 16 Database 7 Digital Marketing 3 Ecommerce 3 Email Server 2 Finance 2 Google 6 HTML-CSS 2 Industries 6 Infrastructure 3 iOS 3 IoT 1 Javascript 5 Latest Technologies 45 Linux 5 LLMs 11 Machine Learning 32 Mobile 3 MySQL 3 Operating Systems 3 PHP 2 Project Management 3 Python Programming 28 SEO - AEO 5 Software Development 49 Software Testing 3 Web Server 7 Work Ethics 2