By ATS Staff - December 21st, 2025
Database Software Development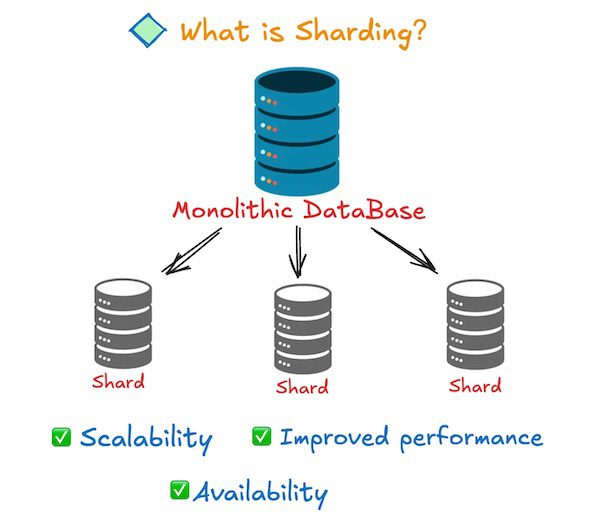
Introduction
In today's data-driven world, applications routinely handle millions of users and petabytes of data. Traditional single-database architectures struggle under such loads, leading to performance bottlenecks, reliability issues, and scaling limitations. Database sharding has emerged as a powerful solution to these challenges, enabling systems to scale horizontally across multiple machines while maintaining performance and availability.
What is Database Sharding?
Database sharding is a horizontal partitioning technique that splits a large database into smaller, more manageable pieces called "shards." Each shard operates as an independent database that contains a subset of the total data. Unlike vertical partitioning (which splits tables by columns) or replication (which copies entire datasets), sharding distributes data across multiple servers based on a specific key or algorithm.
Think of it as dividing a massive library into several smaller specialty libraries—one for fiction, one for history, one for science—rather than building a single enormous building with all books in one place.
How Sharding Works
The Sharding Key
The foundation of any sharding implementation is the sharding key—a specific column or set of columns that determines how data is distributed. Common sharding keys include:
- User ID (for user-centric applications)
- Geographic location
- Tenant ID (for multi-tenant applications)
- Creation timestamp
Sharding Strategies
- Range-Based Sharding: Data is partitioned based on ranges of the sharding key (e.g., users A-F on shard 1, G-L on shard 2). While simple to implement, this can lead to uneven distribution (hotspots) if data isn't uniformly distributed.
- Hash-Based Sharding: A hash function is applied to the sharding key to determine the shard assignment. This typically provides better distribution but makes range queries difficult.
- Directory-Based Sharding: A lookup service maintains a mapping of sharding keys to specific shards. This offers flexibility but introduces a potential single point of failure.
- Geo-Based Sharding: Data is partitioned based on geographic location, which can reduce latency for region-specific queries.
Benefits of Sharding
Improved Performance: By distributing data across multiple machines, sharding reduces the load on any single database server, leading to faster query response times.
Horizontal Scalability: Sharding enables almost limitless scaling by adding more shards as data grows, unlike vertical scaling which hits hardware limitations.
High Availability: Since shards operate independently, a failure in one shard doesn't necessarily bring down the entire system.
Cost Effectiveness: Commodity hardware can be used for shards rather than investing in expensive, high-end servers.
Challenges and Considerations
Increased Complexity: Sharding transforms what was once a simple database operation into a distributed system challenge, requiring sophisticated tooling and expertise.
Cross-Shard Operations: Joins, transactions, and queries that span multiple shards become significantly more complex and slower to execute.
Rebalancing: As data grows unevenly, rebalancing shards (moving data between them) can be resource-intensive and complex.
Schema Changes: Applying schema modifications across all shards requires careful coordination.
Choosing the Right Shard Key: A poor shard key choice can create hotspots or make common queries inefficient.
Real-World Implementation Patterns
Application-Level Sharding: The application code contains logic to route queries to appropriate shards. This offers maximum flexibility but burdens developers.
Proxy-Based Sharding: A middleware layer (like Vitess or ProxySQL) handles shard routing transparently to the application.
Database-Native Sharding: Some databases (like MongoDB, CockroachDB, and Google Spanner) offer built-in sharding capabilities.
Best Practices for Sharding
- Postpone Sharding: Only implement sharding when truly necessary—after optimizing queries, adding caching, and considering read replicas.
- Plan for Growth: Design your sharding strategy with future scaling in mind, including how you'll add new shards.
- Start Simple: Begin with a smaller number of shards and expand as needed.
- Monitor Distribution: Continuously monitor data distribution to prevent hotspots and uneven loading.
- Implement Idempotent Operations: Ensure that operations can be retried safely in case of partial failures.
- Consider Federation First: For multi-tenant applications, consider database-per-tenant approaches before full sharding.
When to Shard (and When Not To)
Consider sharding when:
- Your database is approaching hardware limits despite optimization
- You need to distribute data geographically for performance or compliance
- You're building a multi-tenant SaaS application with large, independent customers
Avoid sharding if:
- Your dataset fits comfortably on a single server with replication
- Most queries require joins across what would be different shards
- Your team lacks distributed systems expertise
- You can solve performance issues with caching or query optimization
The Future of Sharding
Modern database systems are increasingly incorporating automated sharding capabilities. Serverless databases and managed services are abstracting away sharding complexity, allowing developers to benefit from horizontal scaling without managing the intricacies. NewSQL databases promise the scalability of sharding with the ACID guarantees of traditional databases, potentially making manual sharding obsolete for many use cases.
Conclusion
Database sharding remains a critical technique for scaling data-intensive applications, but it's not a silver bullet. Successful implementation requires careful planning, appropriate tooling, and ongoing management. As with any architectural decision, the key is to match the solution to your specific requirements—sharding when necessary, but not before. For organizations facing genuine scalability challenges, a well-implemented sharding strategy can mean the difference between a struggling application and one that scales seamlessly to meet user demand.
The evolution of database technologies continues to make horizontal scaling more accessible, but understanding sharding principles remains essential for architects and developers building the next generation of data-intensive applications.
Popular Categories
Agile 2 Android 2 Artificial Intelligence 51 Backup Tools 2 Blockchain 2 Cloud Storage 5 Code Editors 2 Computer Languages 12 Cybersecurity 9 Data Science 17 Database 8 Digital Marketing 3 Ecommerce 3 Email Server 2 Finance 2 Google 6 HTML-CSS 2 Industries 6 Infrastructure 4 iOS 3 IoT 1 Javascript 6 Latest Technologies 45 Linux 10 LLMs 11 Machine Learning 32 Mobile 3 Msths & Stats 1 MySQL 3 Open source 1 Operating Systems 7 PHP 2 Project Management 3 Python Programming 28 SEO - AEO 5 Software Development 49 Software Testing 3 Web Server 7 Work Ethics 2